The C50 package contains an interface to the C5.0
classification model. The main two modes for this model are:
- a basic tree-based model
- a rule-based model
Many of the details of this model can be found in Quinlan (1993) although the model has new features that are described in Kuhn and Johnson (2013). The main public resource on this model comes from the RuleQuest website.
To demonstrate a simple model, we’ll use the credit data that can be
accessed in the modeldata
package:
The outcome is in a column called Status and, to
demonstrate a simple model, the Home and
Seniority predictors will be used.
## 'data.frame': 4454 obs. of 3 variables:
## $ Home : Factor w/ 6 levels "ignore","other",..: 6 6 3 6 6 3 3 4 3 4 ...
## $ Seniority: int 9 17 10 0 0 1 29 9 0 0 ...
## $ Status : Factor w/ 2 levels "bad","good": 2 2 1 2 2 2 2 2 2 1 ...
# a simple split
set.seed(2411)
in_train <- sample(1:nrow(credit_data), size = 3000)
train_data <- credit_data[ in_train,]
test_data <- credit_data[-in_train,]Classification Trees
To fit a simple classification tree model, we can start with the non-formula method:
##
## Call:
## C5.0.default(x = train_data[, vars], y = train_data$Status)
##
## Classification Tree
## Number of samples: 3000
## Number of predictors: 2
##
## Tree size: 4
##
## Non-standard options: attempt to group attributesTo understand the model, the summary method can be used
to get the default C5.0 command-line output:
summary(tree_mod)##
## Call:
## C5.0.default(x = train_data[, vars], y = train_data$Status)
##
##
## C5.0 [Release 2.07 GPL Edition]
## -------------------------------
##
## Class specified by attribute `outcome'
##
## Read 3000 cases (3 attributes) from undefined.data
##
## Decision tree:
##
## Home in {owner,parents}: good (1946.3/421.6)
## Home in {ignore,other,priv,rent}:
## :...Seniority > 5: good (447.4/100.4)
## Seniority <= 5:
## :...Seniority <= 0: bad (148/46)
## Seniority > 0: good (458.4/204)
##
##
## Evaluation on training data (3000 cases):
##
## Decision Tree
## ----------------
## Size Errors
##
## 4 772(25.7%) <<
##
##
## (a) (b) <-classified as
## ---- ----
## 102 726 (a): class bad
## 46 2126 (b): class good
##
##
## Attribute usage:
##
## 99.93% Home
## 35.17% SeniorityA graphical method for examining the model can be generated by the
plot method:
plot(tree_mod)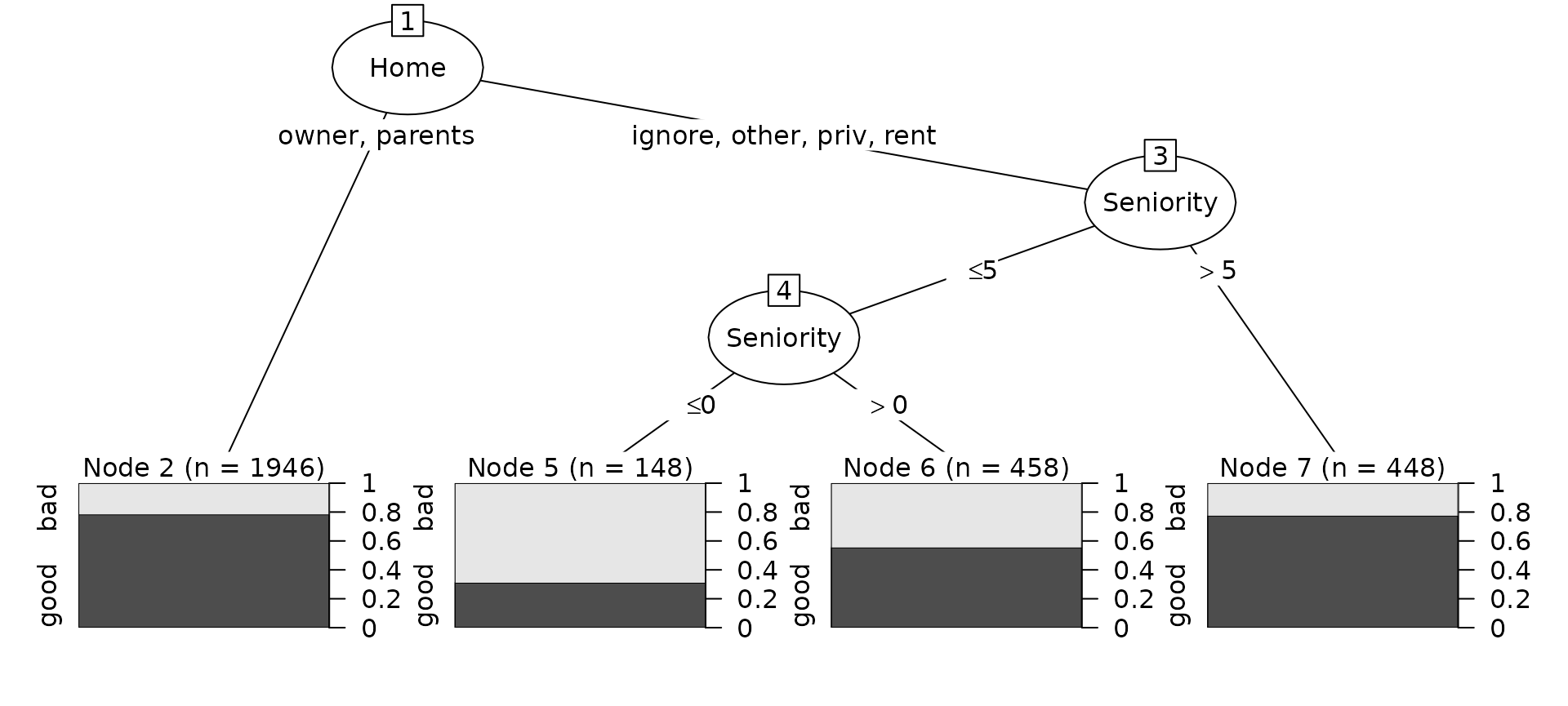
A variety of options are outlines in the documentation for
C5.0Control function. Another option that can be used is
the trials argument which enables a boosting procedure.
This method is model similar to AdaBoost than to more statistical
approaches such as stochastic gradient boosting.
For example, using three iterations of boosting:
##
## Call:
## C5.0.default(x = train_data[, vars], y = train_data$Status, trials = 3)
##
##
## C5.0 [Release 2.07 GPL Edition]
## -------------------------------
##
## Class specified by attribute `outcome'
##
## Read 3000 cases (3 attributes) from undefined.data
##
## ----- Trial 0: -----
##
## Decision tree:
##
## Home in {owner,parents}: good (1946.3/421.6)
## Home in {ignore,other,priv,rent}:
## :...Seniority > 5: good (447.4/100.4)
## Seniority <= 5:
## :...Seniority <= 0: bad (148/46)
## Seniority > 0: good (458.4/204)
##
## ----- Trial 1: -----
##
## Decision tree:
##
## Seniority > 5: good (1330.8/319.3)
## Seniority <= 5:
## :...Home in {ignore,other,priv,rent}: bad (666/280.5)
## Home in {owner,parents}: good (1003.2/448.8)
##
## ----- Trial 2: -----
##
## Decision tree:
##
## Home in {owner,parents}: good (1113.9)
## Home in {ignore,other,priv,rent}:
## :...Seniority <= 0: bad (74.5)
## Seniority > 0: good (1243.5/262.2)
##
##
## Evaluation on training data (3000 cases):
##
## Trial Decision Tree
## ----- ----------------
## Size Errors
##
## 0 4 772(25.7%)
## 1 3 822(27.4%)
## 2 3 772(25.7%)
## boost 772(25.7%) <<
##
##
## (a) (b) <-classified as
## ---- ----
## 102 726 (a): class bad
## 46 2126 (b): class good
##
##
## Attribute usage:
##
## 100.00% Seniority
## 99.93% HomeNote that the counting is zero-based. The plot method
can also show a specific tree in the ensemble using the
trial option.
Rule-Based Models
C5.0 can create an initial tree model then decompose the tree
structure into a set of mutually exclusive rules. These rules can then
be pruned and modified into a smaller set of potentially
overlapping rules. The rules can be created using the rules
option:
rule_mod <- C5.0(x = train_data[, vars], y = train_data$Status, rules = TRUE)
rule_mod##
## Call:
## C5.0.default(x = train_data[, vars], y = train_data$Status, rules = TRUE)
##
## Rule-Based Model
## Number of samples: 3000
## Number of predictors: 2
##
## Number of Rules: 3
##
## Non-standard options: attempt to group attributes
summary(rule_mod)##
## Call:
## C5.0.default(x = train_data[, vars], y = train_data$Status, rules = TRUE)
##
##
## C5.0 [Release 2.07 GPL Edition]
## -------------------------------
##
## Class specified by attribute `outcome'
##
## Read 3000 cases (3 attributes) from undefined.data
##
## Rules:
##
## Rule 1: (148/46, lift 2.5)
## Home in {ignore, other, priv, rent}
## Seniority <= 0
## -> class bad [0.687]
##
## Rule 2: (1945/421, lift 1.1)
## Home in {owner, parents}
## -> class good [0.783]
##
## Rule 3: (2651/641, lift 1.0)
## Seniority > 0
## -> class good [0.758]
##
## Default class: good
##
##
## Evaluation on training data (3000 cases):
##
## Rules
## ----------------
## No Errors
##
## 3 772(25.7%) <<
##
##
## (a) (b) <-classified as
## ---- ----
## 102 726 (a): class bad
## 46 2126 (b): class good
##
##
## Attribute usage:
##
## 93.30% Seniority
## 69.77% HomeNote that no pruning was warranted for this model.
There is no plot method for rule-based models.
Predictions
The predict method can be used to get hard class
predictions or class probability estimates (aka “confidence values” in
documentation).
predict(rule_mod, newdata = test_data[1:3, vars])## [1] good good good
## Levels: bad good
predict(tree_boost, newdata = test_data[1:3, vars], type = "prob")## bad good
## 2 0.0000000 1.0000000
## 12 0.0000000 1.0000000
## 21 0.3008402 0.6991598Cost-Sensitive Models
A cost-matrix can also be used to emphasize certain classes over others. For example, to get more of the “bad” samples correct:
cost_mat <- matrix(c(0, 2, 1, 0), nrow = 2)
rownames(cost_mat) <- colnames(cost_mat) <- c("bad", "good")
cost_mat## bad good
## bad 0 1
## good 2 0##
## Call:
## C5.0.default(x = train_data[, vars], y = train_data$Status, costs = cost_mat)
##
##
## C5.0 [Release 2.07 GPL Edition]
## -------------------------------
##
## Class specified by attribute `outcome'
##
## Read 3000 cases (3 attributes) from undefined.data
## Read misclassification costs from undefined.costs
##
## Decision tree:
##
## Seniority > 5: good (1426/217)
## Seniority <= 5:
## :...Home in {ignore,other,priv,rent}: bad (606.4/300.4)
## Home in {owner,parents}:
## :...Seniority <= 2: bad (606/383)
## Seniority > 2: good (361.6/82)
##
##
## Evaluation on training data (3000 cases):
##
## Decision Tree
## -----------------------
## Size Errors Cost
##
## 4 983(32.8%) 0.43 <<
##
##
## (a) (b) <-classified as
## ---- ----
## 529 299 (a): class bad
## 684 1488 (b): class good
##
##
## Attribute usage:
##
## 100.00% Seniority
## 52.43% Home##
## bad good
## 591 863##
## bad good
## 61 1393